What Is text to speech?
A plain-language guide to the technology that turns written words into spoken audio.

Text to speech in 30 seconds
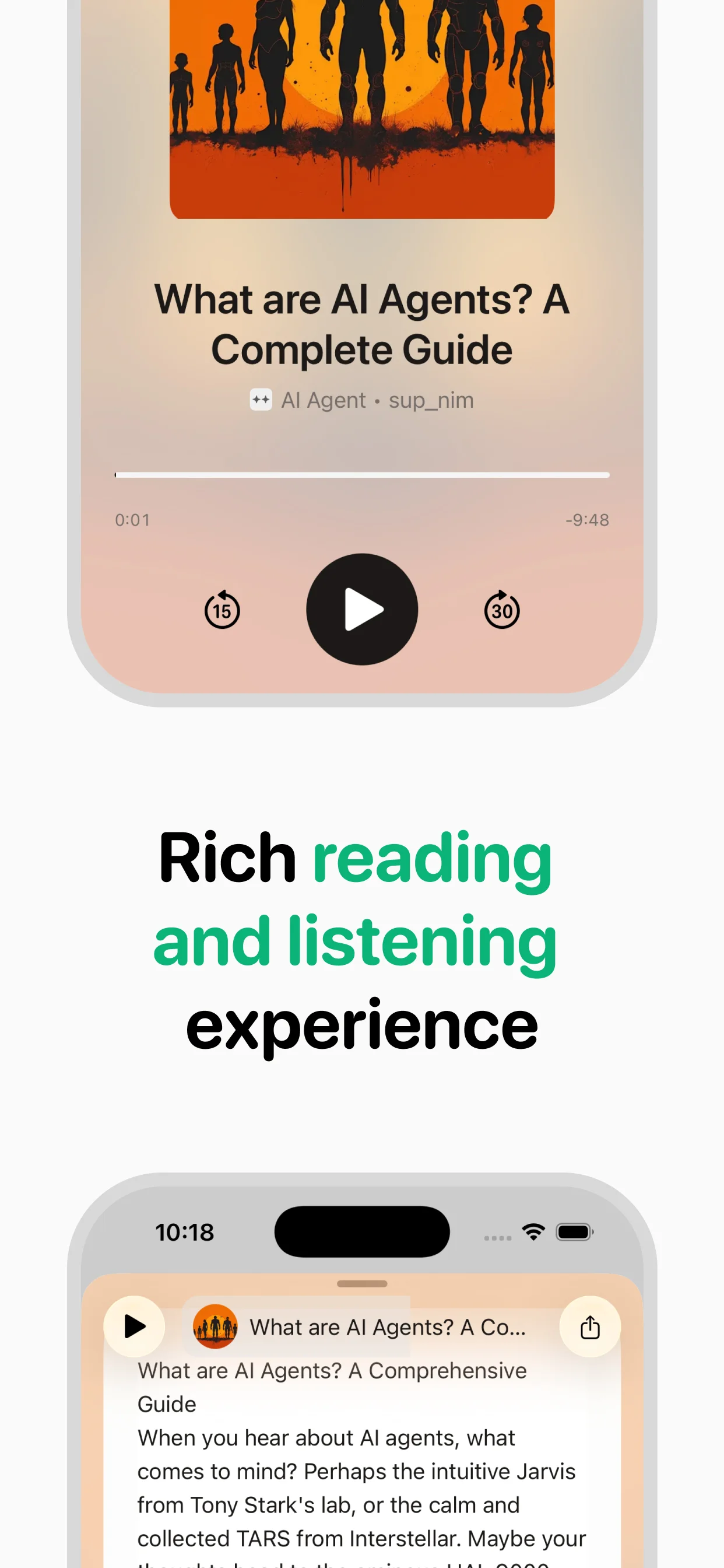
Text to speech (TTS) is technology that converts written text into spoken audio. Modern TTS systems use neural networks trained on thousands of hours of human speech to produce voices that sound remarkably natural — far from the robotic monotone of early systems. You encounter TTS every day: when your phone reads directions aloud, when a screen reader helps someone navigate a website, or when an app like speakeasy converts a long article into audio you can listen to on a walk.
A brief history of speech synthesis
The first mechanical speech synthesizer was built in 1791 by Wolfgang von Kempelen. Electronic speech synthesis began in the 1930s at Bell Labs with the Voder, demonstrated at the 1939 World's Fair. The first computer-based TTS system, developed by Noriko Umeda in 1968, could read English text aloud but sounded distinctly robotic. Through the 1980s and 90s, concatenative synthesis — stitching together pre-recorded speech fragments — improved quality. The real breakthrough came in 2016 when DeepMind released WaveNet, a deep neural network that generated speech waveforms directly, achieving near-human quality for the first time.
How modern TTS engines work
Modern neural TTS follows a pipeline. First, a text analysis module handles pronunciation: expanding abbreviations, interpreting numbers, and converting words into phonemes (speech sounds). Next, an acoustic model — typically a transformer or diffusion network — predicts the acoustic features (mel spectrograms) that describe how the speech should sound. Finally, a vocoder converts those features into an actual audio waveform. The entire process happens in milliseconds on modern hardware. Models like InWorld's neural voices (used by speakeasy) and OpenAI's TTS engine are trained on diverse datasets to handle varied content — from news articles to technical documentation — with natural intonation and pacing.
Types of TTS technology
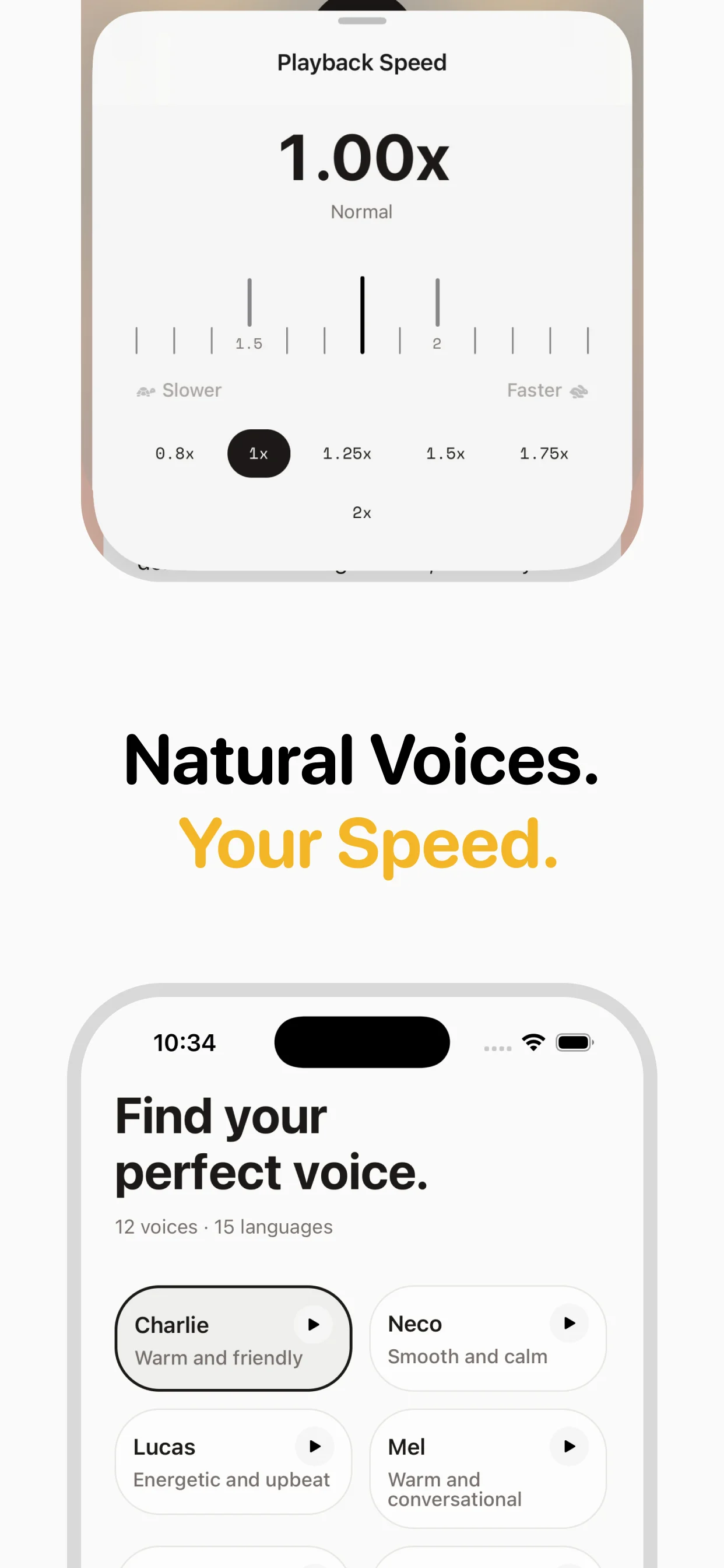
There are three main generations of TTS. Formant synthesis (oldest) uses mathematical models of the vocal tract — fast but robotic. Concatenative synthesis splices together recordings of a human voice, producing more natural results but with audible seams. Neural TTS (current state of the art) uses deep learning to generate speech from scratch, producing the most natural results with proper emphasis, breathing pauses, and emotional inflection. Within neural TTS, you'll see terms like "autoregressive" models (generating audio sample by sample) and "non-autoregressive" models (generating in parallel for faster speed).
Common use cases
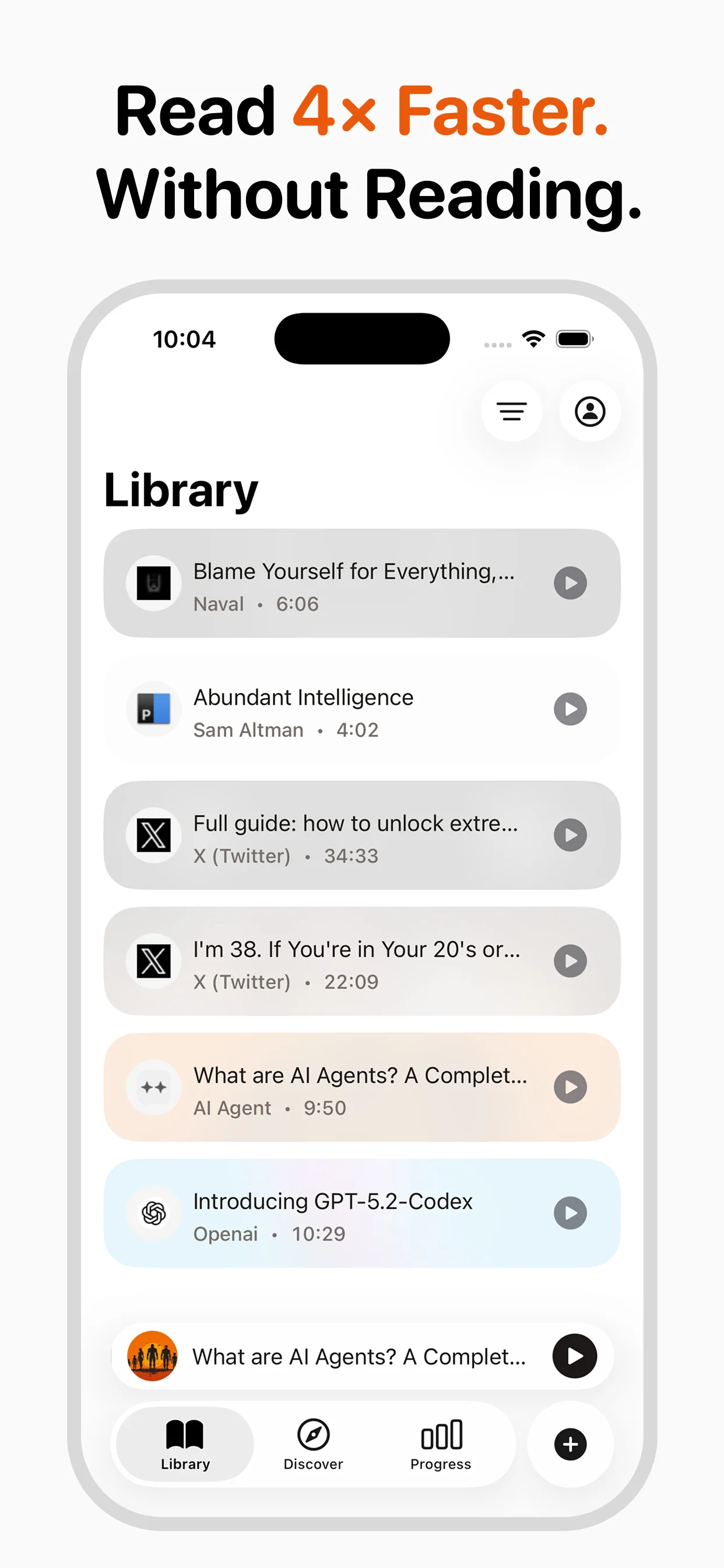
TTS serves accessibility users (screen readers for visually impaired people), language learners (hearing correct pronunciation), commuters (listening to articles and newsletters), content creators (generating voiceovers), customer service (IVR systems and chatbots), and education (reading textbooks and study materials aloud). The fastest-growing segment is personal productivity — people using TTS to convert their reading backlog into audio they can consume during commutes, workouts, or chores.
Frequently asked questions

Turn any article into natural-sounding audio. Paste a link, press play, and stay informed while you move.
Coming soon on Android