How text to speech Works
From raw text to natural-sounding audio — the step-by-step process behind modern TTS.
The TTS pipeline
Every text-to-speech system follows the same basic pipeline: text normalization, linguistic analysis, acoustic modeling, and waveform generation. The input is raw text — an article, an email, a book chapter. The output is an audio file that sounds like a human reading that text aloud. What happens in between has evolved dramatically over the past decade.
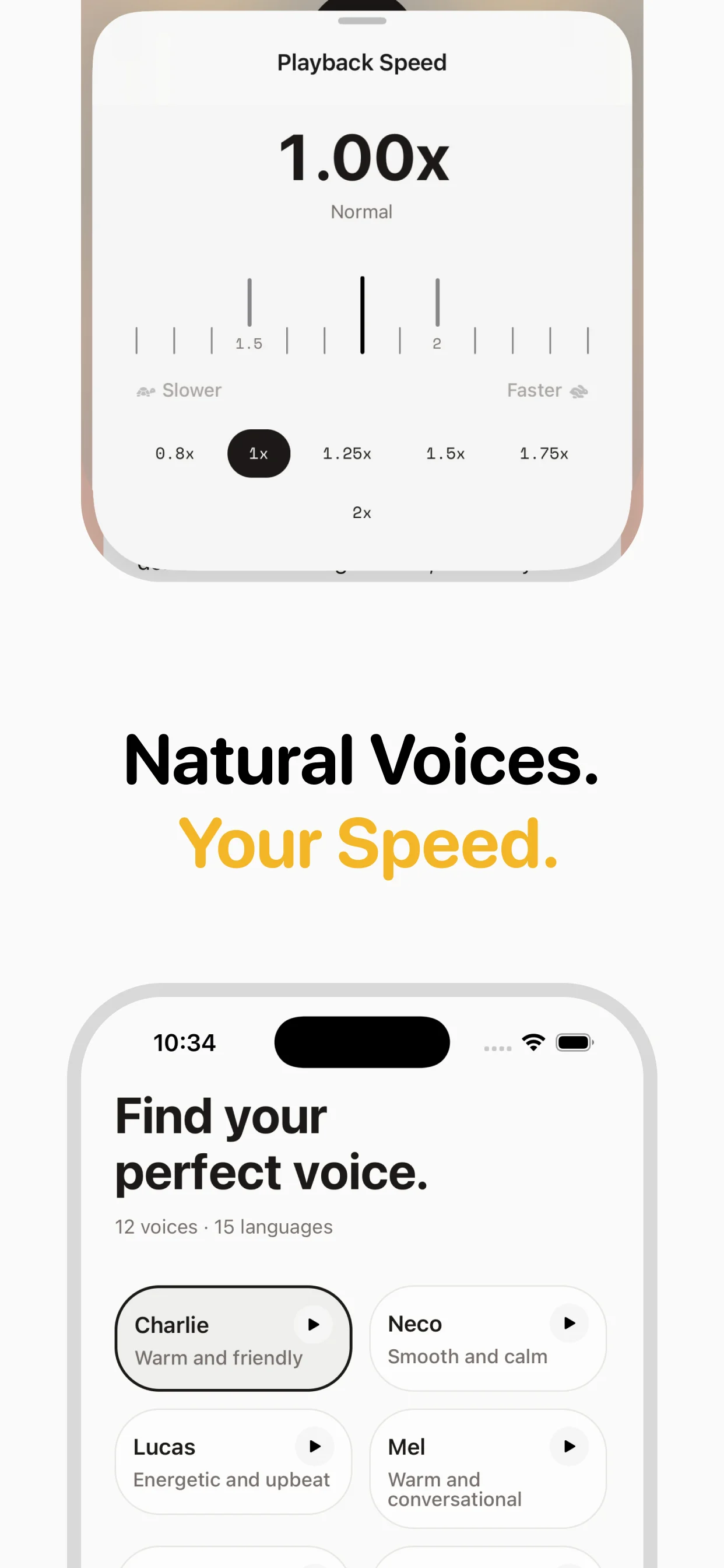
Step 1: Text normalization
Before any speech is generated, the engine must interpret what the text actually means. The number "1,200" could be "one thousand two hundred" or "twelve hundred." The abbreviation "Dr." could be "Doctor" or "Drive." Dates, currencies, acronyms, URLs, and emoji all need special handling. This stage also segments text into sentences and identifies paragraph breaks — critical for getting pauses and intonation right.
Step 2: Linguistic analysis
The engine converts normalized text into a phonetic representation — a sequence of phonemes (distinct speech sounds) with prosodic markers for stress, pitch, and duration. English has about 44 phonemes. The word "through" maps to three phonemes: /θ/ /r/ /uː/. This stage also handles homographs ("read" past tense vs. present tense, "lead" the verb vs. the metal) using surrounding context. Advanced systems perform part-of-speech tagging and dependency parsing to resolve ambiguity.
Step 3: Acoustic modeling
This is where neural networks transformed TTS. The acoustic model takes the phoneme sequence and predicts mel spectrograms — visual representations of how the speech should sound over time. Modern architectures include Tacotron 2 (autoregressive, high quality), FastSpeech 2 (non-autoregressive, faster), and diffusion-based models. These networks learn from hundreds of hours of human speech recordings, capturing not just pronunciation but natural rhythm, emphasis, and breathing patterns.
Step 4: Vocoder (waveform generation)
The vocoder converts the mel spectrogram into an actual audio waveform — the final audio file you hear. Early neural vocoders like WaveNet were extremely slow (minutes to generate one second of audio). Modern vocoders like HiFi-GAN and Vocos generate audio hundreds of times faster than real-time while maintaining high quality. This is why TTS that sounded robotic five years ago now sounds nearly human.
Chunking long content
Real-world TTS engines have input length limits. InWorld's engine, used by speakeasy, has a 2,000-character limit per request. To handle a 5,000-word article, the text is split into chunks at sentence boundaries (typically around 1,800 characters to leave margin). Each chunk is synthesized in parallel for speed, then the audio segments are concatenated with crossfade blending to avoid audible seams. This is why speakeasy can convert a 20-minute article in under 30 seconds.
Frequently asked questions

Turn any article into natural-sounding audio. Paste a link, press play, and stay informed while you move.
Coming soon on Android